
In this work, we systematically study the problem of personalized text-to-image generation, where the output image is expected to portray information about specific human subjects. E.g., generating images of oneself appearing at imaginative places, interacting with various items, or engaging in fictional activities. To this end, we focus on text-to-image systems that input a single image of an individual to ground the generation process along with text describing the desired visual context. Our first contribution is to fill the literature gap by curating high-quality, appropriate data for this task. Namely, we introduce a standardized dataset (Stellar) that contains personalized prompts coupled with images of individuals that is an order of magnitude larger than existing relevant datasets and where rich semantic ground-truth annotations are readily available. Having established Stellar to promote cross-systems fine-grained comparisons further, we introduce a rigorous ensemble of specialized metrics that highlight and disentangle fundamental properties such systems should obey. Besides being intuitive, our new metrics correlate significantly more strongly with human judgment than currently used metrics on this task. Last but not least, drawing inspiration from the recent works of ELITE and SDXL, we derive a simple yet efficient, personalized text-to-image baseline that does not require test-time fine-tuning for each subject and which sets quantitatively and in human trials a new SoTA.
This work studies explicitly and only personalized T2I generators concerning human subjects.
It introduces new specialized metrics that correlate stronger with human judgement compared to existing ones; and offers richly annotated data to help standardize this setup.
It develops a simple, yet efficient personalized generator baseline, StellarNet, which sets a new SoTA, and of which the outputs are preferred by human evaluators more frequently than alternatives (9 times more often than the next best method).
Stellar (Systematic Evaluation of Personalized Imagery) dataset is a large-scale standardized evaluation dataset for human-based personalized T2I generation tasks. Stellar is comprised of 20k carefully curated prompts describing imaginative situations and actions for rendering human-centric fictional images, paired with rich meta-annotations promoting a rigorous evaluation of personalized T2I systems.
The prompts are a combination of human-generated ones (crowdsourced from Amazon Mechanical Turk), denoted as Stellar- and template-based semi-automatically generated prompts, denoted as Stellar-. A small subset of these prompts, together with a corresponding generation template and associated categories (show with a colored circle, e.g., ) can be seen in the table below.
| Stellar- | Stellar- | Template | Category |
|---|---|---|---|
| juggling oranges on a rooftop | juggling apples in the airport | juggling [fruit] [building loc.] | |
| riding a skateboard in outer-space | riding a skateboard near Saturn | riding [vehicle] in the [space loc.] | |
| wrestling an octopus on a pirate boat | fighting a shark on a boat | fighting [animal] in the [vehicle] | |
| as an astronaut walking to a rocket | as an astronaut near a spaceship | as [uniformed] near [space-object] | |
| playing the trombone in a castle | playing the saxophone in a castle | playing [musical instrument] [building loc.] | |
| riding an elephant through the jungles of Thailand | riding a tiger in the jungle | riding [animal] [nature loc.] | |
| eating a croissant at a cafe in Paris | eating a souvlaki in Athens | eating [food] [city] | |
To download the Stellar prompts dataset (20k annotations) please first fill out this form accepting our Terms of Use. You can additionally use this repository to setup the Stellar prompts dataset in a format that could ease the replication of the experiments described in our published manuscript. (This is also necessary for benchmarking your method).
Please note that for our benchmark and experiments we associate the Stellar prompts with 400 unique human identities corresponding to publicly available images of the CelebAMask-HQ Dataset. A subset of such images (denoted as original image) is shown on this webpage.
DISCLAIMER: We do not have any copyright ownership for the images of CelebAMask-HQ and we do not redistribute them.
We introduce three novel metrics to measure the similarity between the input subject's `identity', and the generated output image; (i) a coarse face-similarity metric assessing general identity preservation (IPS) (ii) a fine-grained metric focused on facial attribute preservation (APS), and (iii) a metric orthogonal to the first two, designed to evaluate the sensitivity and robustness of a method in maintaining identity consistency (SIS).
Established metrics assessing text-image similarity (e.g., CLIPT) often fall short in providing granular insights into their scoring rationale; i.e., given a low similarity, it is impossible to reason whether this stems from a failure to depict the semantic objects, the requested interactions, the desired atmosphere or style, or combinations of the above. Thus, we introduce specialized and interpretable metrics to evaluate two key aspects of the alignment between image and prompt; object faithfulness (GOA) and the fidelity of depicted relationships (RFS).
A visual explanation of the metrics can be seen below.
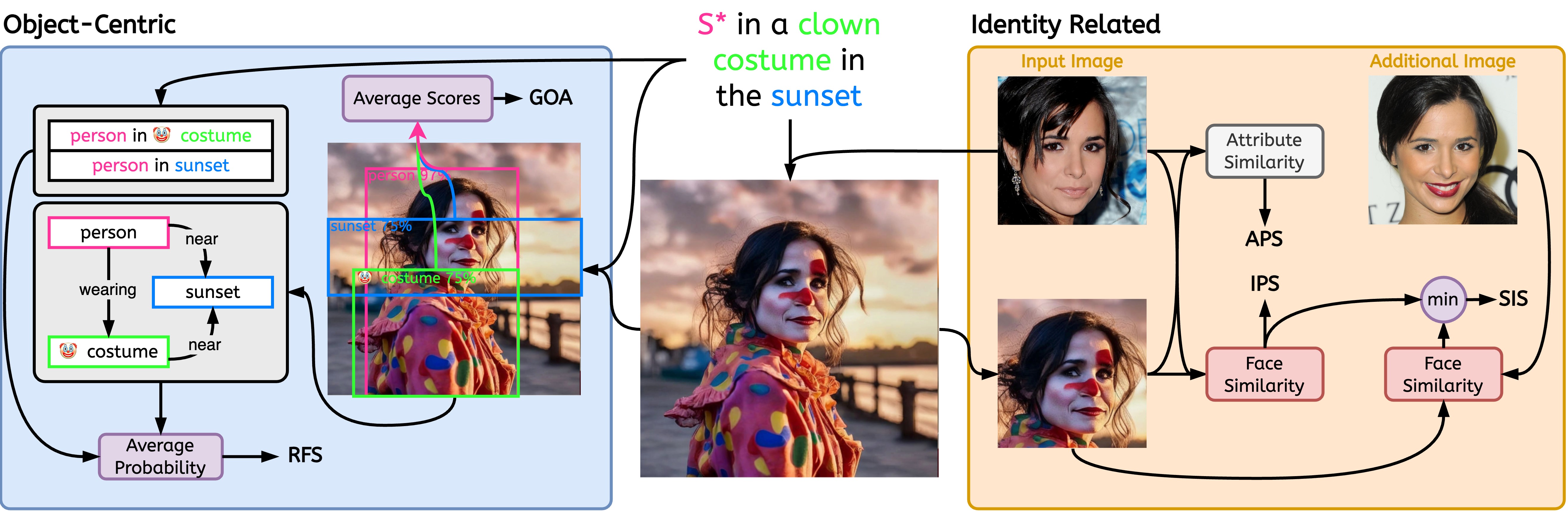
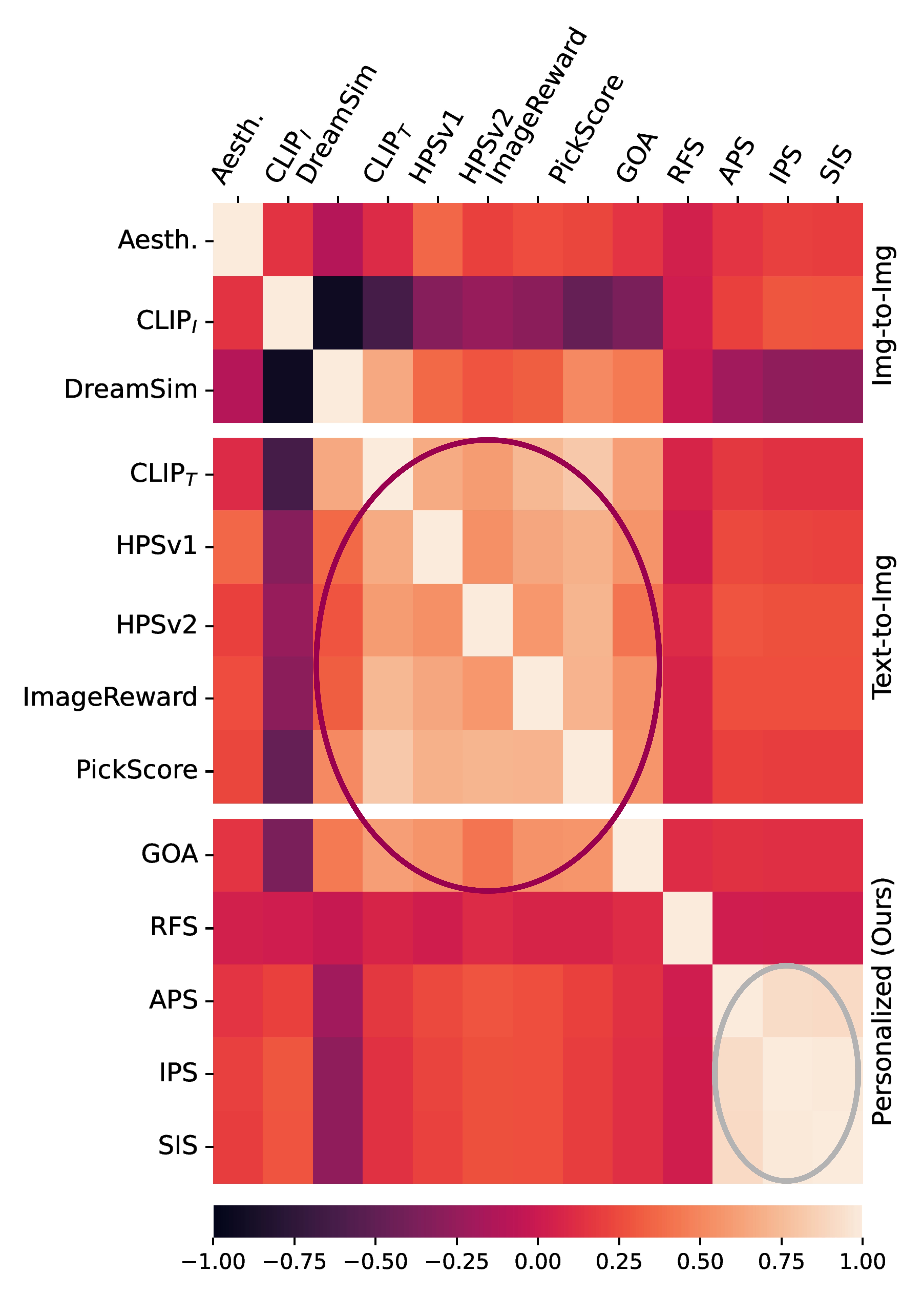
To assess the alignment of ours and pre-existing metrics with human judgment, we study the correlation on the Overall success of the personalized T2I generation, Object-related faithfulness between text and generated image, and Relation-related faithfulness between text and generated image. To this end, we performed AMT studies recieving a total of 2.5k responses and concluding that our metrics correlate significantly better with human-preference on all aspects of evaluation.
| Metric | Human Pref. Kendall - τ | ||
|---|---|---|---|
| Obj | Rel | Overall | |
| CLIPT | 0.130 | 0.089 | 0.106 |
| HPSv2 | 0.067 | 0.004 | 0.224 |
| PickScore | 0.139 | 0.110 | 0.246 |
| DreamSim | 0.031 | 0.132 | 0.270 |
| CLIPI | 0.049 | 0.011 | 0.304 |
| HPSv1 | 0.094 | 0.103 | 0.304 |
| ImageReward | 0.040 | 0.060 | 0.320 |
| Aesth. | 0.049 | 0.146 | 0.359 |
| GOA | 0.175 | 0.110 | 0.149 |
| RFS | 0.121 | 0.163 | 0.167 |
| APS | 0.013 | 0.018 | 0.389 |
| SIS | 0.112 | 0.011 | 0.435 |
| IPS | 0.094 | 0.018 | 0.455 |
The proposed personalized metrics () have a small correlation with Img-to-Img (top) and Text-to-Img () metrics, suggesting they provide an additional dimension by which T2I systems can be evaluated. Note also how the Text-to-Img metrics have high correlation with GOA but very little correlation with RFS, indicating that they mostly assess the faithful representation of the contextual prompt objects in the image and not their interactions.
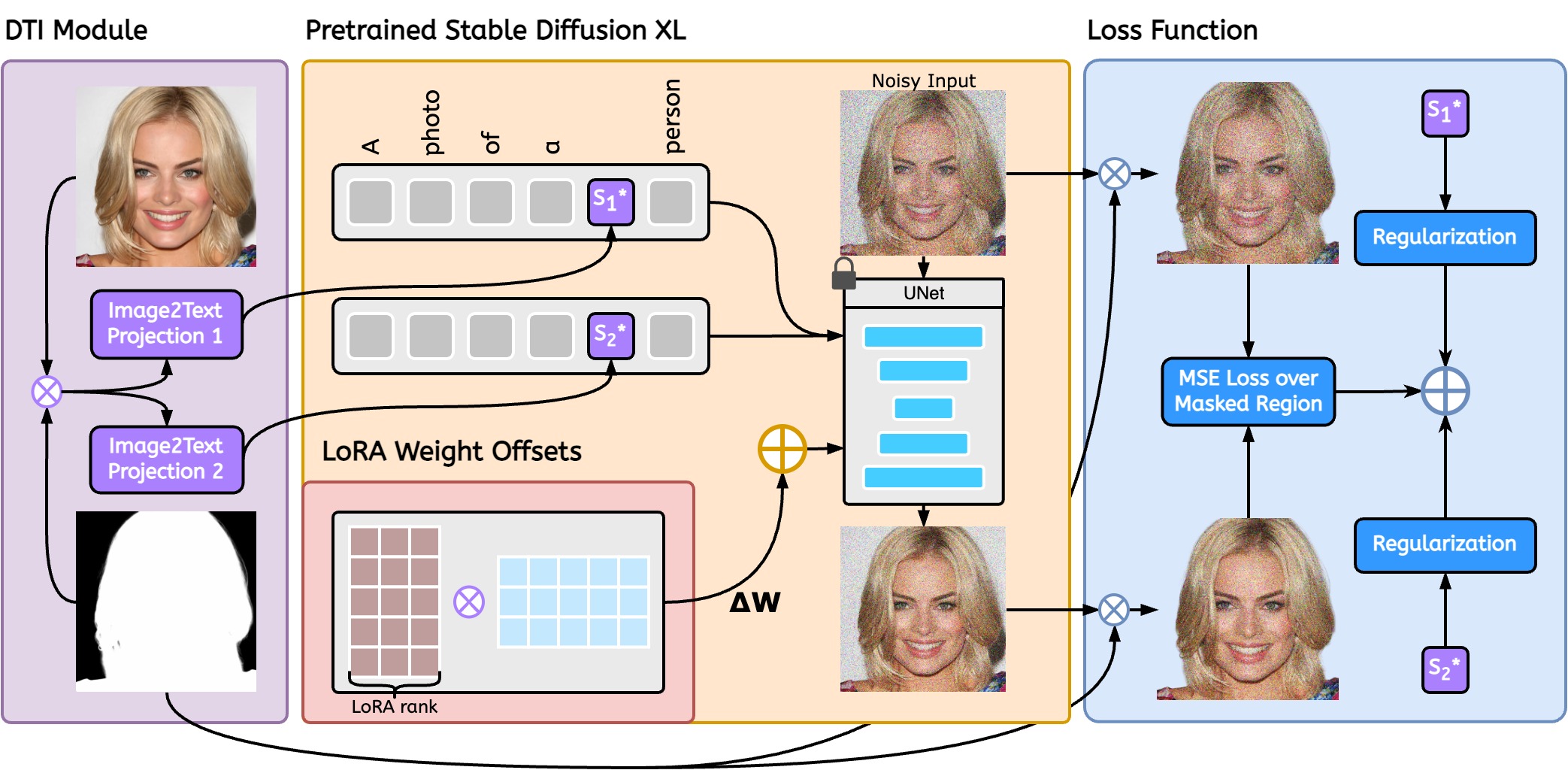
Given a prompt and an input image for a subject, we invert the foreground-masked identity image into textual embeddings, S* (left). The S* augments the textual prompt passed to the pre-trained text-to-image model (SDXL) to guide the model into generating images with the given identity (middle). Additionally, we finetune the UNet backbone of SDXL using LoRA weight-offsets for efficient and stable training (middle bottom). To avoid unnecessary penalization of the model we apply a masked MSE loss during training over the input image and the output generation (right). It is essential to note that during inference, we do not perform any per-subject optimization
Our primary objective is not to devise a new personalized T2I paradigm but to meaningfully enrich our comparative assessment pool. Secondarily, we wish to highlight the potential of leveraging more powerful open-source, non-personalized T2I systems (e.g., SDXL) in combination with well-curated data (e.g., CelebAMask-HQ) to assist personalized generators.
Using the results from our Overall Human Preference Study, we find StellarNet's generations to be preferred, against three established personalized generators (ELITE*, Dreambooth, Textual Inversion), in 78.1% of all trials, compared to 8.7% for the second best method (ELITE*). Additionally, we evaluate all 4 methods on our introduced metrics, as well as CLIPT, HPSv1, HPSv2, PickScore, DreamSim, ImageReward, CLIPI and Aesthetic Score and we find a significant agreement, with all metrics (except from CLIPT) prefering our method's outputs.
Qualitatively, on the image below we show same examples of StellarNet's generations compared other personalized T2I methods. Coupled with every image there are 5 colored circles representing the preference of the 5 distinct metrics shown on the bottom of the figure. An opaque circle, e.g., , means this image has the highest score for this metric compared to the other images in the row.

Note also how the last row on the image underlines the significance and complementarity of APS and IPS metrics. Where IPS coarse face similarity does not accurately discern StellarNet's improved capture of the input subject's identity due to changes in non-invariant characteristics like eyeglasses, the fine-grained nature of APS manages to effectively showcase our method's enhanced ability to represent this identity.
The Stellar-prompt dataset is released under the Stellar Terms of Use. Our evaluation code is released under the following license and the following third-party licenses. Our dataset code is released under the following license and the following third-party licenses.
If you find our work useful in your research, please consider citing:
@article{stellar2023,
author = {Achlioptas, Panos and Benetatos, Alexandros and Fostiropoulos, Iordanis and Skourtis, Dimitris},
title = {Stellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods},
volume = {abs/2312.06116},
journal = {Computing Research Repository (CoRR)},
year = {2023},
}The authors wish to express their gratitude to Michelle Ritter for supporting and enabling the fruition of this project and Ioannis Papapanagiotou, Stephanie Bousley, Ran Rabinowitch and John Boyd for their essential help in managing various administrative and logistical aspects throughout its development. Furthermore, they wish to thank the fantastic Turkers of Amazon Mechanical Turk, whose help in curating the introduced dataset was pivotal.
* All authors made very significant and distinct contributions.